SmartPLS adalah perangkat lunak yang digunakan untuk analisis jalur parsial berbasis keragaman (partial least squares path modeling) dalam penelitian. Ini adalah alat yang populer dalam analisis data untuk menguji model konseptual dan hubungan antarvariabel.
Berikut adalah langkah-langkah umum dalam melakukan analisis data menggunakan SmartPLS:
Persiapan Data: Siapkan data Anda dalam format yang sesuai. Biasanya, data yang digunakan dalam SmartPLS harus berupa data skala interval atau rasio. Pastikan data Anda lengkap dan siap untuk dianalisis.
Membuat Model: Identifikasi model konseptual Anda dan buat model struktural yang mencerminkan hubungan antarvariabel yang ingin Anda analisis. Model ini dapat berupa diagram yang menggambarkan hubungan antarvariabel dan hipotesis yang diajukan.
Memasukkan Data ke SmartPLS: Impor data Anda ke dalam SmartPLS. Ini melibatkan memasukkan variabel dan nilai pengamatan yang sesuai ke dalam perangkat lunak. Pastikan variabel yang tepat telah ditentukan sebagai variabel dependen atau independen sesuai dengan model Anda.
Pengolahan Data: SmartPLS akan melakukan praproses data untuk menghilangkan nilai yang hilang atau tidak valid, melakukan normalisasi jika diperlukan, dan menghitung statistik yang relevan. Pastikan untuk memeriksa apakah praproses data telah dilakukan dengan benar.
Mengevaluasi Model: SmartPLS akan memberikan analisis statistik tentang model Anda, termasuk signifikansi koefisien jalur, nilai R-squared, dan lain-lain. Ini akan membantu Anda mengevaluasi sejauh mana model Anda sesuai dengan data Anda.
Menginterpretasi Hasil: Interpretasikan hasil analisis untuk memahami hubungan antarvariabel, signifikansi koefisien jalur, dan pengaruh variabel-variabel tertentu dalam model. Perhatikan bahwa interpretasi hasil ini harus dilakukan dengan hati-hati dan sesuai dengan konteks penelitian Anda.
Melaporkan Hasil: Buat laporan atau artikel yang menjelaskan hasil analisis Anda menggunakan SmartPLS. Jelaskan temuan Anda, interpretasikan hasil, dan berikan penjelasan yang memadai untuk mendukung temuan Anda.
Selain langkah-langkah di atas, penting juga untuk mempelajari dokumentasi SmartPLS yang tersedia, serta literatur yang relevan tentang analisis jalur parsial dan konsep statistik yang mendasarinya. Ini akan membantu Anda memahami lebih baik konsep dan teknik yang terlibat dalam analisis data dengan SmartPLS.
Seperti Paket Perbaikan tradisional, rilis modifikasi ini menyertakan banyak peningkatan kualitas, tetapi dengan manfaat tambahan dari tambahan baru tersebut.
Prosedur dan Peningkatan Statistik
Uji-Z dan interval kepercayaan untuk Proporsi dan perbedaan dalam Proporsi: Untuk analisis Satu Sampel, Sampel Berpasangan, Sampel Independen.
Ditemukan di bawah menu Analyze> Compare Means, prosedur Proportions baru memungkinkan pengguna untuk menguji perbedaan dalam proporsi populasi dan membangun interval kepercayaan pada perbedaan yang diamati menggunakan berbagai metode untuk setiap jenis analisis.
Sebagai bagian dari prosedur Keandalan, McDonald’s Omega memungkinkan pengguna alternatif dari statistik Alpha Cronbach. Untuk menemukan peningkatan ini, buka Analisis> Skala> Analisis Keandalan, dan di bawah Model tarik-turun pada dialog Analisis Keandalan, pilih Omega.
Tonton video tentang McDonald’s Omega di SPSS Statistics 27.0.1.0 di sini .
Peningkatan Korelasi Bivariat: Interval Keyakinan yang Ditambahkan
Peningkatan dalam Statistik SPSS 27.0.1.0 ini dapat ditemukan di menu dialog Korelasi Bivariat di bawah sub dialog Interval Keyakinan. Pengguna akan dapat mengatur parameter interval kepercayaan, menerapkan penyesuaian bias jika diinginkan untuk Korelasi Pearson, dan memilih di antara berbagai metode untuk koefisien korelasi lainnya.
Tonton video tentang peningkatan Interval Keyakinan Korelasi Bivariat di sini .
Bersamaan dengan tambahan baru di atas, kami juga menyertakan interval kepercayaan untuk keluaran CONTRAST dalam ANOVA satu arah, menambahkan bootstrap dan beberapa imputasi ke Proporsi, dan membuat peningkatan pada beberapa pencocokan rata-rata prediktif imputasi untuk mengaktifkan kemampuan untuk memilih jumlah pencocokan potensial kasus.
Peningkatan Kegunaan
Manajemen Sesi: Pulihkan Poin
Ekstensi untuk fungsi pemulihan otomatis yang diperkenalkan dalam SPSS Statistics 27.0.0.0 memungkinkan pengguna untuk menyimpan titik waktu dalam analisis mereka sehingga pengguna dapat kembali ke sana jika diperlukan nanti dalam analisis, sambil tetap memungkinkan pengguna untuk melanjutkan analisis saat ini. jalan. Manajemen Sesi ditemukan di Dialog Selamat Datang di tab Restore Points di sebelah tab Recent Files dan Sample Files. Pada tab Restore Points, pengguna akan menemukan file Auto-Recovery mereka, serta Restore Points yang disimpan.
Pelajari cara mendapatkan hasil maksimal dari Titik Pemulihan Manajemen Sesi dengan menonton videonya di sini .
Peningkatan Output: Pengalaman Editor
Beberapa peningkatan telah diperkenalkan di SPSS Statistics 27.0.1.0 untuk Pembuat Grafik, serta Editor Tabel & Bagan. Peningkatan ini mengurangi jumlah klik yang diperlukan untuk mendapatkan keluaran yang dapat disesuaikan dalam aplikasi dengan memanfaatkan tambahan dan pengalaman toolbar baru.
Pelajari cara memanfaatkan penyempurnaan untuk menyesuaikan keluaran di sini .
Penyempurnaan SPSS Statistics Syntax juga diperkenalkan dalam SPSS Statistics 27.0.1.0 yang memungkinkan pengguna untuk memilih variabel dari kumpulan data aktif menggunakan fungsi mengetik di depan. Ini akan meningkatkan efisiensi dalam menulis skrip dan memudahkan pengguna untuk menemukan variabel yang benar sebagai referensi dari kumpulan data aktif.
Peningkatan Kualitas: Seiring dengan peningkatan fitur dan produktivitas baru, ada juga beberapa peningkatan kualitas yang dilakukan pada aplikasi untuk 27.0.1.0. Daftar perbaikan tersebut dapat ditemukan di sini .
Informasi Produk Tambahan
Mengupgrade ke macOS Big Sur? Baca blog ini untuk mempelajari tentang masalah umum.
Jika Anda sudah memiliki versi 27.0.0.0 dan ingin meningkatkan ke 27.0.1.0, unduh penginstal baru dari situs web IBM Passport Advantage atau melalui Fix Central untuk Windows , macOS , Linux .
Kabar baik: Kode otorisasi perangkat lunak versi 27 Anda akan berfungsi dengan versi baru dan akan diterapkan secara otomatis ketika Anda menginstalnya pada mesin yang saat ini memiliki versi 27.
Pengenalan EViews
Eviews (Econometric Views) adalah software pengolahan data yang digunakan untuk berbagai
keperluan mulai dari Bisnis, Riset Internal serta penelitian. EViews menawarkan akses statistik yang kuat
kepada peneliti akademis, perusahaan, instansi pemerintah, dan siswa seperti peramalan (forecasting),
hubungan (Correlation), pengaruh dan sebagainya dengan antar muka (user interface) yang lebih friendly dan
mudah digunakan.
Gambar 1 : Proses Pengolahan Data
a. Uji Asumsi Klasik
1. Uji Multikolinearitas
Uji multikolinearitas bertujuan untuk menguji apakah model regresi terbentuk adanya korelasi tinggi
atau sempurna antar variabel bebas (independen). Jika ditemukan ada hubungan korelasi yang tinggi antar
variabel bebas maka dapat dinyatakan adanya gejala multikorlinear pada penelitian.
2. Uji Autokorelasi
Uji autokolerasi merupakan kolerasi yang terjadi antara residual pada satu pengamatan dengan
pengamatan lain pada model regresi. Autokorelasi dapat diketahui melalui Uji Durbin-Watson (D-W
Test), adalah pengujian yang digunakan untuk menguji ada atau tidak adanya korelasi serial dalam model
regresi atau untuk mengetahui apakah di dalam model yang digunakan terdapat autokorelasi diantara
variabel-variabel yang diamati
3. Uji Heteroskedastisitas
Uji heteroskedastisitas digunakan untuk mengetahui ada atau tidaknya penyimpangan asumsi klasik.
Heteroskedastisitas yaitu adanya ketidaksamaan varian dari residual untuk semua pengamatan pada model
regresi. Prasyarat yang harus terpenuhi dalam model regresi adalah tidak adanya gejala heteroskedastisitas.
4. Uji Normalitas
Uji normalitas untuk menguji apakah nilai residual yang telah distandarisasi pada model regresi
berdistribusi normal atau tidak. Cara melakukan uji normalitas dapat dilakukan dengan pendekatan analisis
grafik normal probability Plot. Pada pendekatan ini nilai residual terdistribusi secara normal apabila garis
(titik-titik) yang menggambarkan data sesungguhnya akan mengikuti atau merapat ke garis diagonalnya.
b. Uji Kelayakan Model (Goodness of Fit)
Uji kelayakan model adalah uji R2
untuk melihat kemampuan variable independen dalam menjelaskan
variable dependen. Nilai R2
berkisar antara 0 – 99, nilai R Square yang semakin mendekati 1 maka semakin
layak suatu model untuk digunakan.
c. Uji Parsial (Uji t)
Uji partial (uji t) adalah uji yang dilakukan untuk melihat apakah suatu variable independen
berpengaruh atau tidak terhadap variable dependen dengan membandingkan nilai thitung dengan ttabel.
Kriteria pengujian uji t adalah sebagai berikut :
– Jika nilai thitung > ttabel maka hipotesis di tolak, artinya variable tersebut berpengaruh terhadap variable
dependen.
– Jika nilai thitung < ttabel maka hipotesis di terima, artinya variable tersebut tidak berpengaruh terhadap
variable dependen.
d. Uji Simultan (Uji F)
Uji Simultan (uji F) adalah uji yang dilakukan untuk melihat apakah semua variable independen secara
bersama-sama berpengaruh atau tidak terhadap variable dependen dengan membandingkan nilai Fhitung dengan
Ftabel.
– Jika nilai Fhitung > Ftabel maka hipotesis di tolak, artinya secara bersama-sama variable independen
tersebut berpengaruh terhadap variable dependen.
– Jika nilai Fhitung < Ftabel maka hipotesis di terima, artinya secara bersama-sama variable independen
tersebut tidak berpengaruh terhadap variable dependen.
Regresi Linear Sederhana
Regresi linear sederhana adalah regresi linear yang terdiri dari 1 variabel dependen (Y) dan 1
variabel independen (X).
Yt=β0 + β1X1t+ εt
Dimana :
Y : Variabel Dependen
X : Variabel Independen
ε : error term (Standar Error)
t : menunjukkan jenis data berupa data runtun waktu (Time Series)
Uji-uji yang perlu dilakukan :
– Uji Normalitas
– Uji Autokorelasi
– Uji Heteroskedastistas
“ Uji Multikolinearitas TIDAK dilakukan dalam regresi liear sederhana karena hanya terdiri dari 1
variabel independen”.
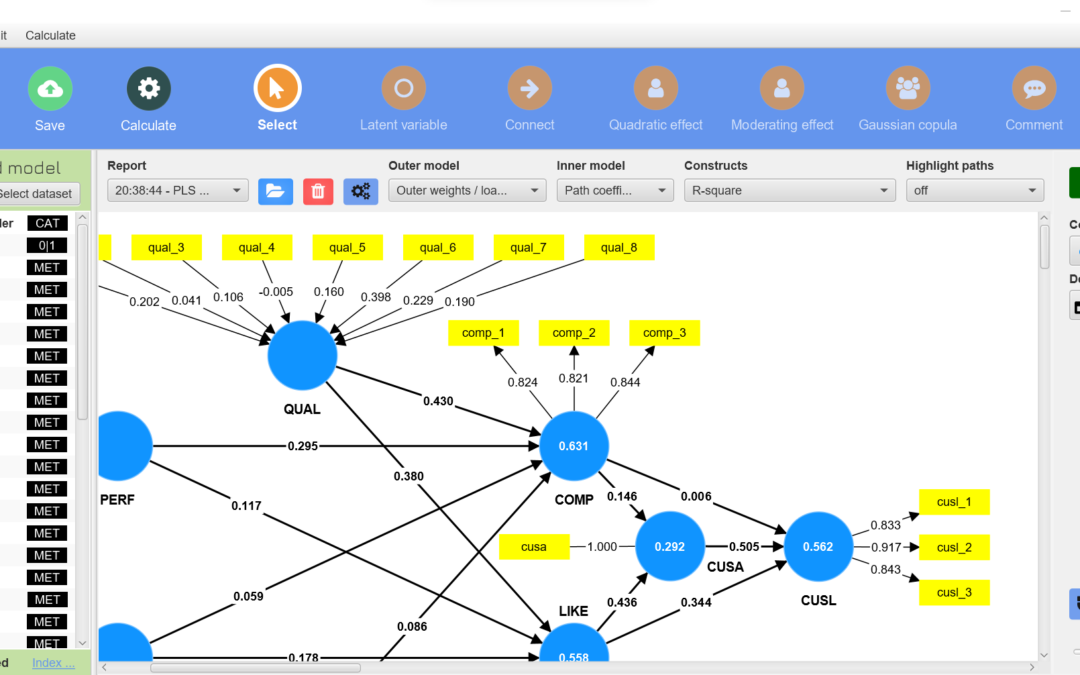
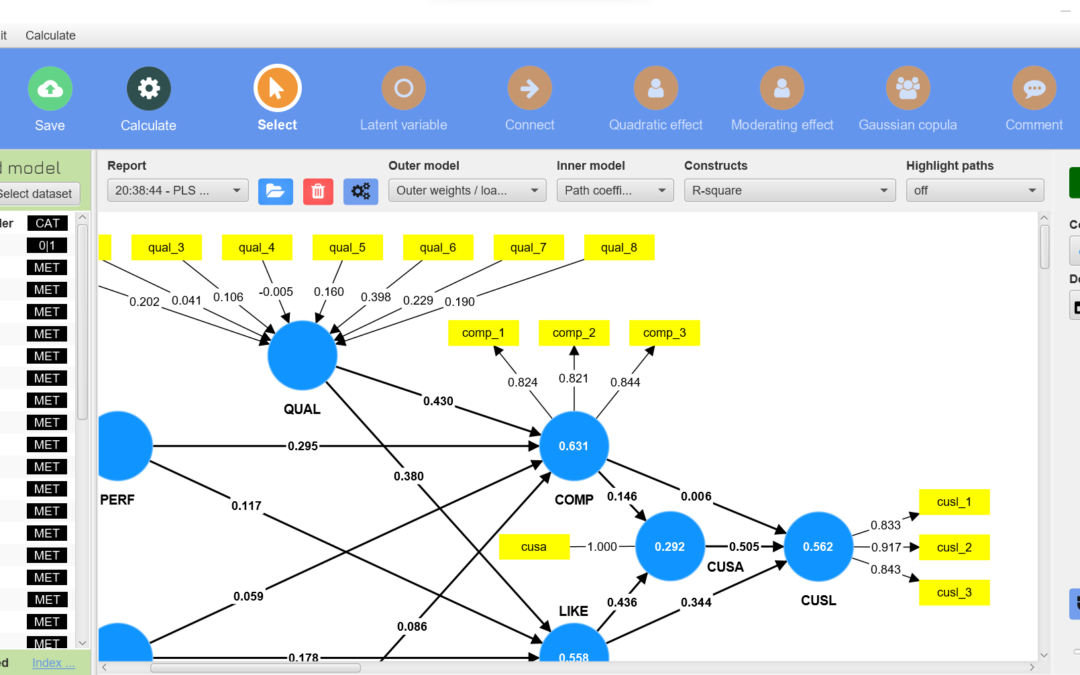
Analisis SEM (Structural Equation Modelling) Dengan SMARTPLS (Partial Least Square)
Analisis SEM (Structural Equation Modelling) Dengan SMARTPLS (Partial Least Square)
Structural Equation Modelling
Pemodelan Persamaan Struktural (Structural Equation Modelling) atau lebih dikenal dengan SEM memiliki beberapa sebutan lain, seperti analisis struktur kovarian (covariance structure analysis), analisis variabel laten (latent variable analysis) analisis faktor konfirmatori (confirmatory factor analysis) dan analisis Linier Structural Relations (Lisrel) (Hair, dkk. 1998). Berdasarkan sebutan-sebutan tersebut, SEM dapat dideskripsikan sebagai suatu analisis yang menggabungkan pendekatan analisis faktor (factor analysis), model struktural (structural model) dan analisis jalur (path analysis). SEM merupakan suatu metode analisis statistik multivariat. Melakukan olah data SEM berbeda dengan melakukan olah data regresi atau analisis jalur. Olah data SEM lebih rumit, karena SEM dibangun oleh model pengukuran dan model struktural. Structural Equation Modeling (SEM) adalah sekumpulan teknik statistika yang memungkinkan pengujian sebuah rangkaian hubungan yang relatif rumit yang tidak dapat diselesaikan oleh persamaan regresi linear. SEM dapat juga dianggap sebagai gabungan dari analisis regresi dan analisis faktor. Disisi lain disebut juga Path Analysis atau Confirmatory factor Analysis, karena keduanya merupakan jenis-jenis khusus dari SEM. Hubungan tersebut dapat dibangun antara satu atau beberapa variabel dependen dengan satu atau beberapa varibel independen Di dalam SEM terdapat 3 (tiga) kegiatan secara bersamaan, yaitu pemeriksaan validitas dan reliabilitas instrumen (confirmatory factor analysis), pengujian model hubungan antara variabel (path analysis), dan mendapatkan model yang cocok untuk prediksi (model struktural dan analisis regresi). Sebuah pemodelan lengkap pada dasamya terdiri dari model pengukuran (measurement model) dan structural model atau causal model. Model pengukuran dilakukan untuk menghasilkan penilaian mengenai validitas dan validitas diskriminan, sedangkan model struktural, yaitu pemodelan yang menggambarkan hubungan-hubungan yang dihipotesakan. Untuk melakukan olah data SEM dengan lebih mudah dapat menggunakan bantuan software statistik. Saat ini sudah tersedia berbagai macam software untuk olah data SEM diantaranya adalah Lisrel, AMOS dan Smart PLS. Dalam memudahkan kita mengolah data dengan analisa statistika dapat menggunakan berbagai macam alat bantu atau software. Adapun software statistika yang dapat digunakan sangatlah banyak namun tidak semuanya memiliki keakuratan yang baik. Ada beberapa software statistika yang sering digunakan baik dalam dunia pendidikan ataupun dalam bidang yang lain yaitu : SPSS (Statistical Package for the Social Software), Minitab, SAS (Statistical Analysis System), Lisrel (Linear Structural Relationship), SMARTPLS (PARTIAL LEAST SQUARE), AMOS (Analysis of Moment Structure), EVIEWS (Economic Views), R-Software, STATA (Statistika dan Data). Kelebihan SMARTPLS 1. Smart PLS atau Smart Partial Least Square adalah software statistik yang sama tujuannya dengan Lisrel dan AMOS yaitu untuk menguji hubungan antara variabel. 2. Pendekatan smartPLS dianggap powerful karena tidak mendasarkan pada berbagai asumsi.
3. Jumlah sampel yang dibutuhkan dalam analisis relatif kecil. Penggunaan Smart PLS sangat dianjurkan ketika kita mememiliki keterbatasan jumlah sampel sementara model yang dibangung kompleks. hal ini tidak dapat dilakukan ketika kita menggunakan kedua software di atas. Lisrel dan AMOS membutuhkan kecukupan sampel. 4. Data dalam analisis smartPLS tidak harus memiliki distribusi normal karena SmartPLS menggunakan metode bootstraping atau penggandaan secara acak. Oleh karenanya asumsi normalitas tidak akan menjadi masalah bagi PLS. Selain terkait dengan normalitas data, dengan dilakukannya bootstraping maka PLS tidak mensyaratkan jumlah minimum sampel. 5. SmartPLS mampu menguji model SEM formatif dan reflektif dengan skala pengukuran indikator berbeda dalam satu model. Apapun bentuk skalanya (rasio kategori, Likert, dam lain-lain) dapat diuji dalam satu model.
Langkah-Langkah Pengolahan Data dengan SmartPLS yaitu : Download
DAMPAK KONSELING INDIVIDU DAN KONSELING BERPASANGAN TERHADAP PENGGUNAAN KONTRASEPSI PASCASALIN: RANDOMIZED CONTROLLED TRIALS (RCT)
DAMPAK KONSELING INDIVIDU DAN KONSELING BERPASANGAN TERHADAP PENGGUNAAN KONTRASEPSI PASCASALIN: RANDOMIZED CONTROLLED TRIALS (RCT)
Pengertian Analisis Data
Program keluarga berencana memiliki makna yang strategis, komprehensif dan fundamental dalam mewujudkan manusia Indonesia yang sehat dan sejahtera. Penelitian yang dilakukan oleh Mujiati1 menjelaskan mengenai UU Nomor 52 Tahun 2009 tentang perkembangan kependudukan dan pembangunan keluarga menyebutkan bahwa keluarga berencana adalah upaya untuk mengatur kelahiran anak, jarak, dan usia ideal melahirkan, mengatur kehamilan, melalui promosi, perlindungan, dan bantuan sesuai hak reproduksi untuk mewujudkan keluarga yang berkualitas.1 Berdasarkan penelitian Glasier2 di negara-negara dengan tingkat kelahiran yang tinggi, keluarga berencana bermanfaat baik untuk kesehatan ibu dan bayi, dengan diperkirakan dapat menurunkan 32% kematian ibu dengan mencegah kehamilan yang tidak diinginkan dan dapat menurunkan 10% kematian anak, dengan mengurangi jarak persalinan kurangdari 2 tahun. Salah satu upaya dalam meningkatkan pemakaian kontrasepsi adalah dengan konseling. Konseling merupakan suatu upaya untuk meningkatkan kualitas sumber daya manusia dalam rangka meningkatkan kesadaran, kemauan serta kemampuan untuk hidup sehat termasuk didalamnya mengenai kesehatan reproduksi guna mendukung terwujudnya pembangunan kesehatan yang lebih baik. Konseling kontrasepsi dapat membantu calon atau pasangan suami istri untuk mengambil keputusan serta mewujudkan kesehatan reproduksi sehingga upaya konseling dapat berperan dalam menurunkan angka kematian ibu.3 Kontrasepsi sebaiknya digunakan pada waktu atau sebelum melakukan hubungan seksual untuk pertama kalinya setelah melahirkan.4 Hingga saat ini masih banyak juga ibu-ibu yang menolak menggunakan kontrasepsi. Penelitian yang dilakukan Romero-Guttierrez menjelaskan bahwa dari 1025 responden didapatkan 50% menggunakan kontrasepsi dan 50% tidak menggunakan kontrasepsi. Beberapa alasan yang disampaikan adalah karena minimnya informasi yang didapatkan sehingga menunda memakai kontrasepsi hingga periode postpartum berakhir. Selain itu mereka juga beranggapan bahwa memakai kontrasepsi mengurangai kenyamanan dalam melakukan hubungan seksual.5 Pada beberapa penelitian ditemukan bahwa salah satu yang mempengaruhi konseling pada pemakaian kontrasepsi adalah karena dukungan suami, seperti penelitian yang dilakukan oleh Romero-Guttierrez dimana 50% ibu postpartum menolak menggunakan kontrasepsi karena tidak ada dukungan suami.5 Sejalan dengan penelitian Prataya itu persetujuan dari pihak suami sangat berpengaruh pada pemakaian kontrasepsi karena adanya persamaan persepsi antara suami dan istri.6 Tana Paser merupakan ibu kota Kabupaten Paser di Provinsi Kalimantan Timur dimana pusat pelayan kesehatan menjadi rujukan dari seluruh kecamatan termasuk klinik bersalinnya. Dari hasil studi pendahuluan didapatkan bahwa konseling sering kali tidak menjadi perhatian utama sehingga data konseling sulit ditemukan. Ditemukannya fakta di lapangan bahwa sebagian besar ibu postpartum tidak mendapatkan konseling KB yang sesuai standar serta jarang ditemukan adanya keterlibatan suami saat melakukan konseling. Penulisan ini merupakan bagian dari tesis dengan judul “Penggunaan Konseling Individu dan Berpasangan Pada Utilisasi Kontrasepsi Pasca Persalinan: Randomized Controlled Trials (RCT)”
METODE
Disain penelitian ini adalah kuantitatif eksperimental dengan menggunakan rancangan penelitian Randomised Controlled Trials (RCT) dengan non blinding yaitu memberikan intervensi berupa konseling kepada individu dan berpasangan. Tempat penelitian ini adalah di Klinik Bersalin Permata Bunda dan Klinik Bersalin Sayang Ibu Kabupaten Paser. Waktu yang dipilih oleh peneliti adalah selama tiga bulan dengan pertimbangan masa follow up yang dilakukan adalah 42 hari. Populasi dalam penelitian ini adalah ibu hamil trimester ketiga yang memeriksakan diri ke klinik bersalin Permata Bunda dan Sayang Ibu kabupaten Paser dan bertempat tinggal di kabupaten Paser. Subjek atau sampel penelitian ini adalah ibu hamil pada trimester ke tiga yang telah memenuhi kriteria inklusi dan eksklusi. Cara pengambilan sampel berdasarkan Sastroasmoro dan Ismael dilakukan dengan simple random sampling yaitu semua subjek yang datang dan memenuhi inklusi akan dipilih secara acak sampai jumlah sampel yang diperlukan terpenuhi.8 Dilakukan randomisasi untuk menentukan subjek mana yang masuk dalam kelompok intervensi atau kelompok kontrol. Analisis univariabel dilakukan untuk mendapatkan gambaran karakteristik masingmasing variabel penelitian dengan menggunakan distribusi frekuensi dan proporsi. Analisis bivariabel bertujuan untuk mengetahui hubungan antara variabel bebas (konseling) dengan variabel terikat (utilisasi kontrasepsi pascapersalinan), varibel luar dengan variabel terikat dan variabel luar dengan variabel bebas. Uji statistik yang digunakan adalah uji chisquare dengan CI 95% dan tingkat kemaknaan p<0,05. Analisis multivariabel bertujuan untuk mengetahui pengaruh variabel bebas terhadap variabel terikat secara bersama-sama dengan mengontrol variabel luar. Analisis multivariabel yang digunakan adalah dengan uji binomial regresi logistik dengan tingkat kemaknaan sebesar P ><0,05 dengan CI95%. Analisis univariabel, bivariabel dan multivariabel tersebut dilakukan dengan menggunakan software Stata.21> <0,05. Analisis multivariabel bertujuan untuk mengetahui pengaruh variabel bebas terhadap variabel terikat secara bersama-sama dengan mengontrol variabel luar. Analisis multivariable yang digunakan adalah dengan uji binomial regresi logistik dengan tingkat kemaknaan sebesar P <0,05 dengan CI95%. Analisis univariabel, bivariabel dan multivariabel tersebut dilakukan dengan menggunakan software Stata.
")